数据库与文件系统
数据库文件系统
1 | |
可以查看数据库文件存储的位置 ,每个数据库都对应数据目录下的一个子目录,或者说对应一个文件夹,我们每当我们新建一个数据库时, MySQL 会帮我们做这两件事儿:
- 在 数据目录 下创建一个和数据库名同名的子目录(或者说是文件夹)。
- 在该与数据库名同名的子目录下创建一个名为 db.opt 的文件,这个文件中包含了该数据库的各种属性,比方说该数据库的字符集和比较规则是个啥。
innodb是如何存储表数据的
- innoDB是使用页为基本单位来管理存储空间的,默认页的大小为16kb.
- 对于InnoDB来说,每个索引都对应者一颗B+树,该B+树的每个节点都是一个数据页,数据页之间不必要是物理连续的,因为数据页之间有双向链表来维护着这些页的顺序.
- InnoDB的聚簇索引的叶子节点存储了完整的用户记录,也就是所谓的索引即数据,数据即索引.
为了管理这些页,设计们提出了表空间或文件空间的概念,表空间是一个抽象的概念,可以对应文件系统上一个或者多个真实文件,每个表空间可以被划分为很多很多页.表空间有不同的类型,下面来看看:
系统表空间
系统表空间对应文件系统上一个或多个实际的文件,我们表中的数据都会被默认存储到这个系统表空间. InnoDB不会把各个表的数据存储到系统表空间中,而是为每一个表建立一个独立表空间,使用独立表空间会在该表所属的子目录下创建一个文件名和表名相同的扩展名为.ibd的文件.
比方说假如我们使用独立表空间去存储xiaohaizi数据库下的test表,那么会在xiaohaizi目录下创建test.frm与test.idb
数据目录下有还一些其他文件:
- 服务器进程文件
- 服务器日志文件
比如常规的查询日志,错误日志,二进制日志,redo日志 - 默认/自动生成的SSL和RSA证书和密钥文件
InnoDB的表空间
表空间中存储了各种页
区
为了更好的管理页,InnoDB设计者提出了区的概念,连续的64个页就是区(也就是一个区默认占用1MB空间大小),每256个区划分成1组,大概如下图所示: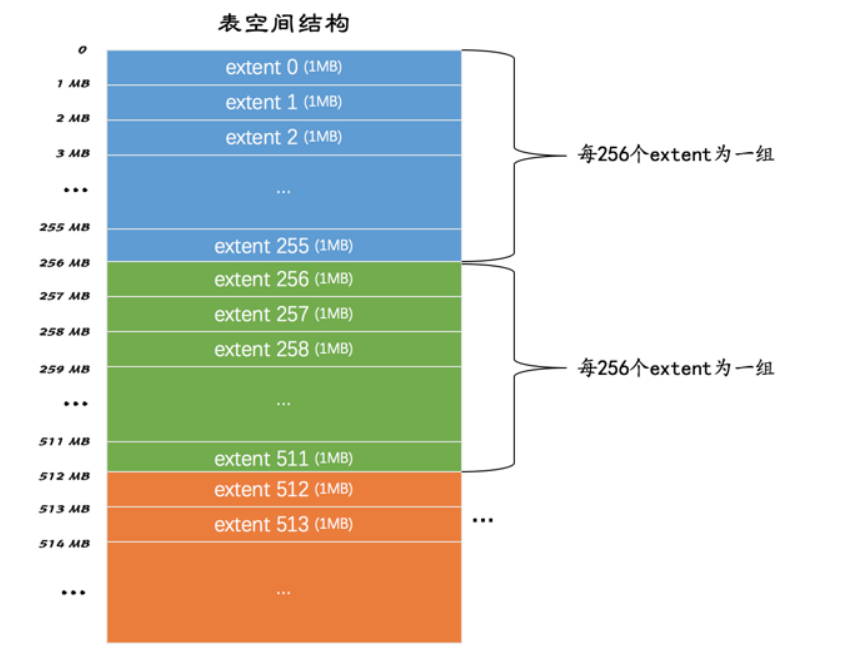
为什么要引入区的概念?
我们每向表中插入一条记录,本质上就是向该表的聚簇索引以及所有二级索引代表的B+树的节点插入数据,而B+树的每一层的页都会形成一个双向链表,如果是以页为单位来分配存储空间的话,双向链表相邻的两个页之间的物理位置可能隔的非常远,如果链表中相邻的两个页的物理位置离的非常远,就是所谓的随机IO,所以应该让链表中相邻的页的物理位置也相邻,这样可以使用所谓的顺序IO,所以才引入了区的概念,一个区就是在物理位置上连续的64个页,为某个索引分配空间的时候不再按照页为单位分配了,而是按照区为单位分配,甚至在表数据非常多的时候,可以一次性分配多个连续的区,虽然可能造成空间浪费,但是可以提高性能.
我们知道范围查询其实是对B+树叶子节点中的记录进行顺序扫描,而如果不区分叶子节点和非叶子节点,统统把节点代表的页面放到区中,进行范围扫描效果就没有那么好,所以叶子节点有自己独有的区,非叶子节点也有自己独有的区存放叶子节点的区的集合就算一个段,存放非叶子节点的区的集合也算一个段,也就是索引会生成两个段,一个叶子节点段,一个非叶子节点段.
区的分类
- 空闲的区:现在还没有用到这个区的任何页面
- 有剩余空间的碎片区:表示碎片区中还有可用的页面
- 没有剩余空间的碎片区:表示碎片区中的所有页面都可以被使用,没有空闲页面.
- 附属于某个段的区.每个索引都可以分为叶子节点和非叶子节点,还有一些特殊作用的段.
为了方便管理这些区,设计了一个XDEC Entry的结构,每个区都对应着一个XDEC Entry结构,这个结构对应了区的一些属性,
- Segment ID
每一个段都有一个唯一编号,这里表示该区所在的段 - List Node
这个部分可以将XDES Entry结构组成一个链表
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!