从数据页到索引
数据页
数据页是InnoDB管理内存空间的基本单位,InnoDB有不同类型的页,比如存放头部空间的页,存放node信息的页,存放undo日志的页,存放表中记录的页,被官方称为索引。
数据页的结构
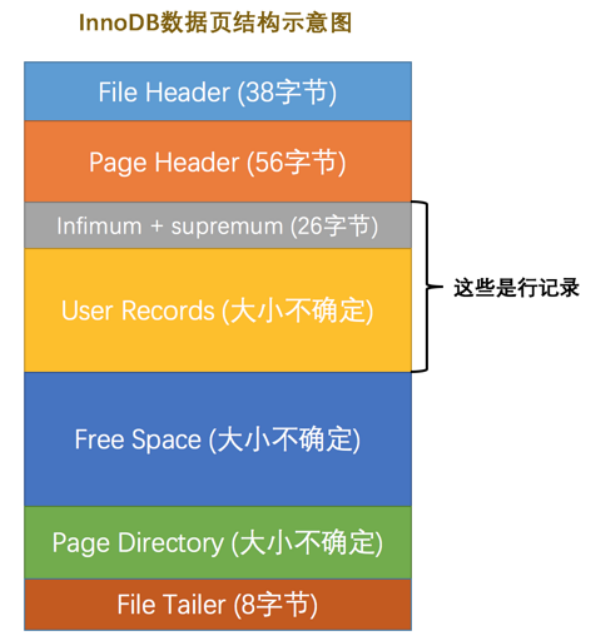
看一下各个部分的简单介绍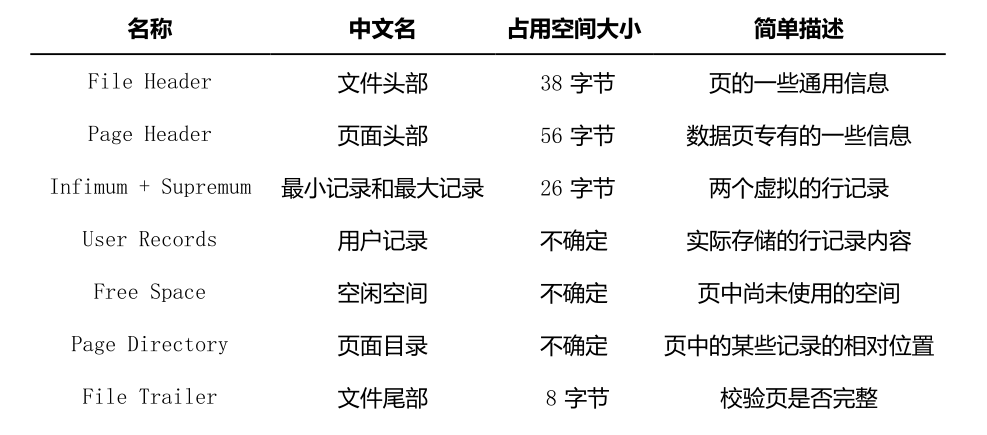
我们自己存储的记录会按指定的行格式存储到User Records部分,每插入一条记录,都会从Free Space 部分,也就是尚未使用的存储空间申请一个记录大小空间划分到User Records部分。
创建一个案例:
1 | |
看一下示例表的行格式:
我们再复习下记录头信息里的各个属性: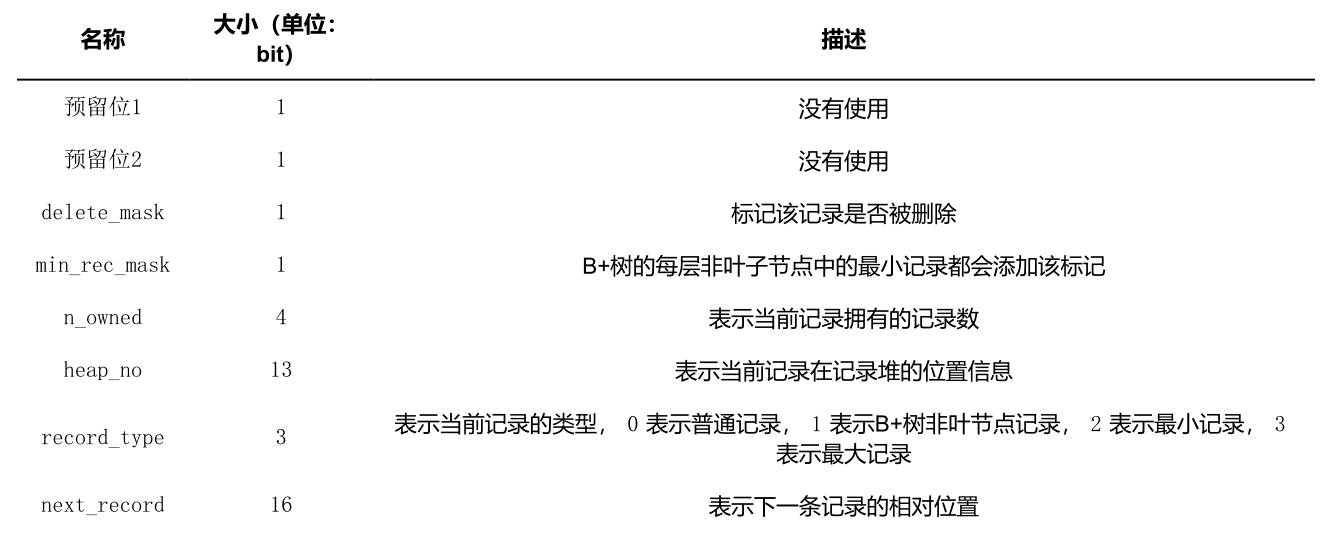
我们向表中插入几条数据:
1 | |
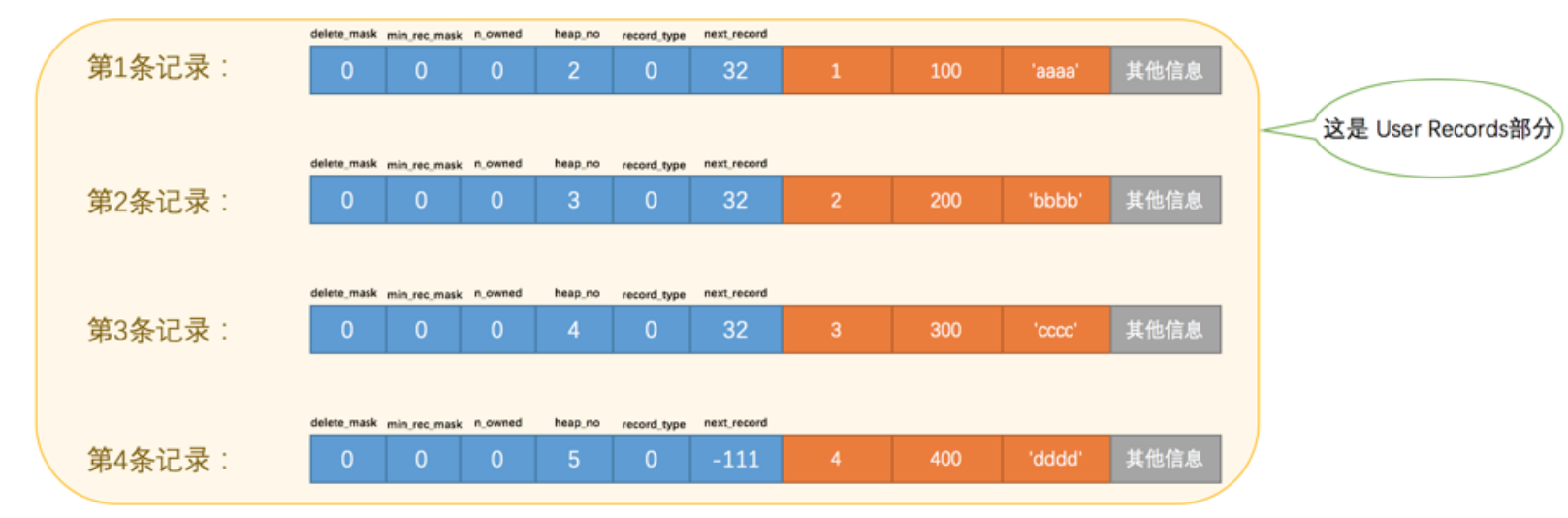
delete_mask:
标志着数据是否被删除,所有被删除的记录都会组成一个垃圾链表,这个链表被称为可重用空间,如果之后又新记录插入到表中,可能把这些空间覆盖掉
min_rec_mask:
B+树的每层非叶子节点中的最小记录都会添加该记录,插入的4条记录的min_rec_mask值都是0,意味着他们都不是B+书的非叶子节点中的最小记录。
heap_no:
表示当前记录在本页中的位置,InnoDB存在两个伪记录,一个代表最小记录,一个代表最大记录,记录怎么比大小,比较记录的大小就是比较主键的大小,但是不管向页中插入多少记录,两条伪纪录都是固定的,如图所示: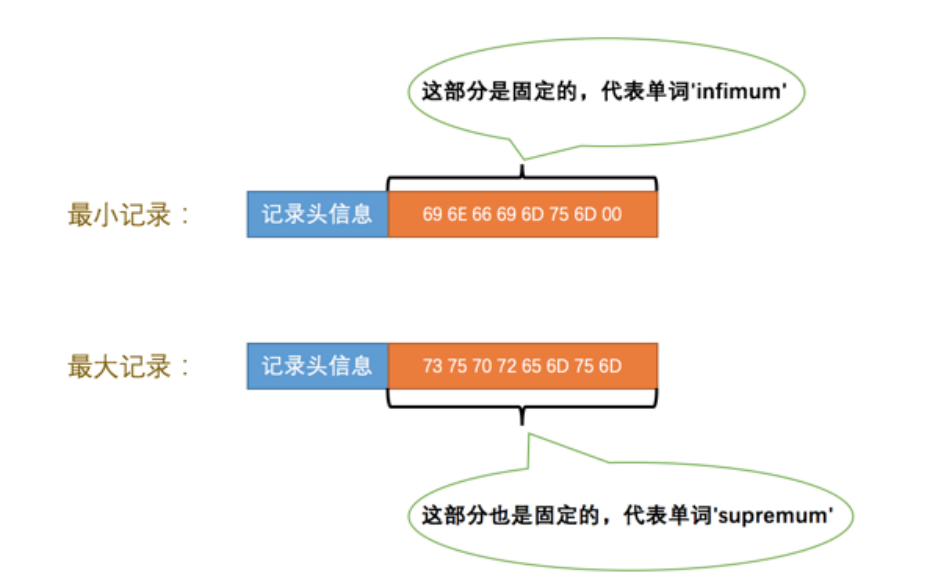
这两条记录被单独放在Infimum+Supremum部分。 最小记录和最大记录的heap_no值分别是0和1,也就是说他们的位置最靠前。
record_type:
这个属性表示记录的类型,0表示普通记录,1表示B+书非叶子节点记录,2表示最小记录,3表示最大记录。
next_record:
表示从当前记录的真实数据到下一条记录真实数据的地址偏移量,可以通过一条记录找到它的一条记录,这其实是个链表,下一条记录指的并不是按照我们插入顺序的下一条记录,而是按照主键值由小到大的顺序的下一条记录,而且规定最小记录的下一条记录就是本页中主键值最小的用户记录,而本页中主键值最大的用户记录的下一条记录就是最大记录.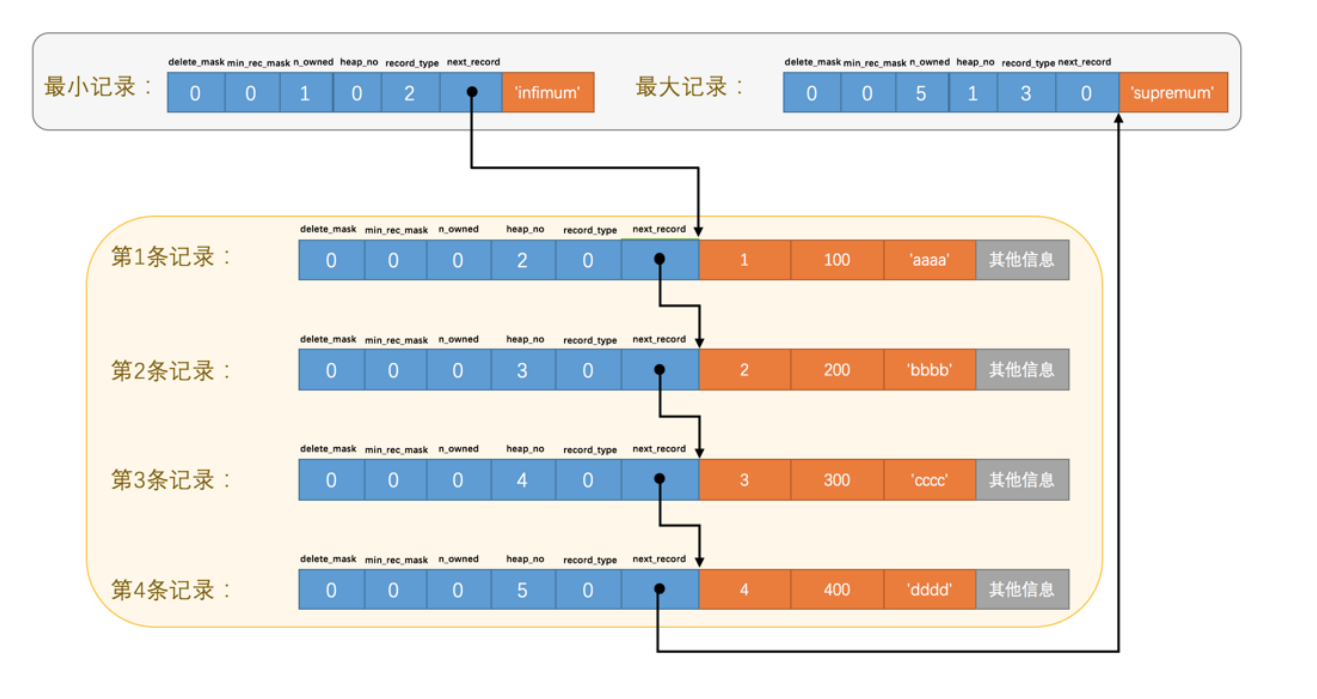
当我们把第2条记录删除: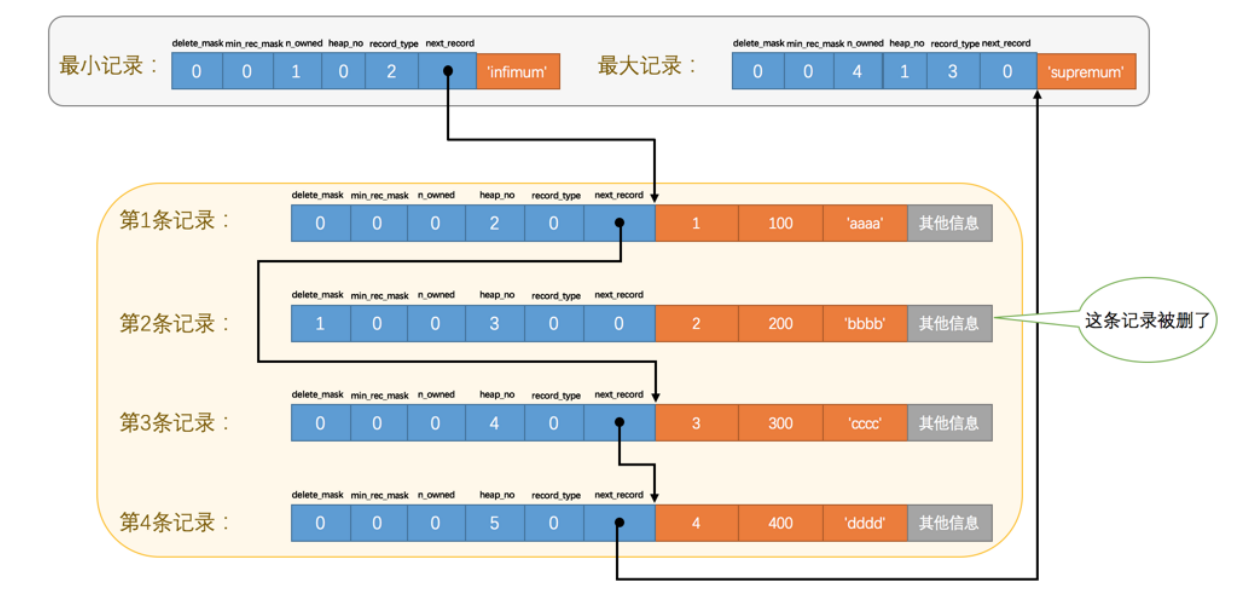
删除第二条记录后我们可以发现这些变化:
- 第二条记录并没有从存储空间移除,而是把该条记录的delete_mask值设置为1
- 第二条记录的next_record值变成0,表示该记录没有下一条记录
- 第一条记录的next_record指向了第三条记录
- 最大记录的n_owned值变成了4
Page Directory(页目录)
普通的一条查询语句,最笨的方法是从最小记录开始,沿着链表一直往后找,但是mysql设计者想到了更好的办法,从目录中得到如下方式:
- 将所有正常的记录(包括最大记录和最小记录)划分为几个组
- 每个组的最后一条记录的头信息中的n_owned属性表示该组拥有多少条记录
- 将每个组的最后一条记录的地址偏移量单独提取出来按顺序存储到Page Directory,也就是页目录,页目录中的这些地址偏移量被称为槽点(slot),所以这个页面目录就是由槽组成的.
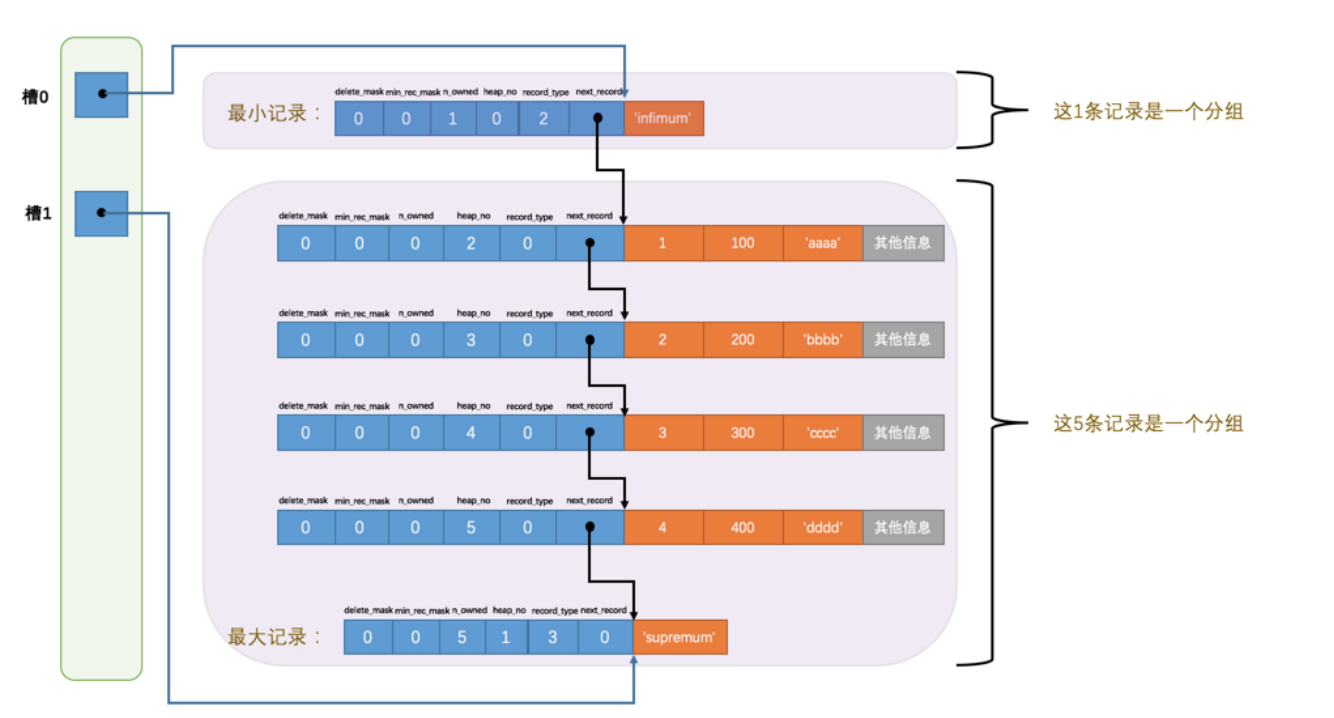
对于最小记录所在的分组只能有1条记录,最大记录所在的分组拥有的记录条数只能在1~8条之间,剩下的分组中记录的条数在4-8条之间,所以分组是按照下边的步骤进行的:
- 初始情况下一个数据页里只有最小记录和最大记录两条,属于两个分组
- 之后每插入一条数据,都会从页目录中找到主键值比本记录值大并且差值最小的槽,然后把该槽对应的记录的n_owned值加1,直到组内有8条数据
- 在一个组的记录等于8时,再插入一条数据时,会将组拆分为两个组,一个组中4条记录,另一个5条记录,并在页目录中新增一个槽来记录这个新增分组的最大记录偏移量.
所以在一个数据页中查找指定主键值的记录的过程分为两步:
- 通过二分法确定该记录所在的槽,并找到该槽中主键值最小的那条记录
- 通过记录的next_record属性遍历该槽所在的组中的各个记录
页面头部
为了能得到一个数据页中存储的记录的状态信息,比如本页中已经存储了多少记录,第一条记录的地址是什么,页目录中存储了多少个槽等等.这些信息存储在Page Header部分.
文件部分
File Header 主要记录了页的一些通用信息,比如这个页的编号是多少,它上一个页,下一个页是多少等等
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!